搜索引擎广告泛滥,XX文库质量低下,网盘速度缓慢,互联网上充斥着各种让人头疼的问题。某度的声誉确实不太好,但不可否认,它曾在国内互联网领域占据过重要地位。尽管如此,瘦死的骆驼比马大,某偶尔还是有一些实用的功能。
例如,某旗下的飞桨(PaddlePaddle)推出了一款名为 PaddleOCR 的开源项目。这是一个基于飞桨的多语言 OCR 工具库,支持超过 80 种语言的识别。其核心亮点之一是一个仅需 8.6MB 的超轻量模型包,就能高效完成 OCR 识别任务。
虽然这些东西很不错,但是仍然存在一定的门槛,一般用户直接使用并不容易。
Umi-OCR(电脑)****
Umi-OCR是GitHub上一位名为hiroi-sora的用户基于PaddleOCR开发的本地OCR识别工具,显著降低了普通用户使用高级项目的门槛
软件无需安装,解压后双击即可启动!

截图OCR、批量OCR、批量文档处理以及二维码识别等常用功能基本齐全。
截图OCR功能可以通过截图的方式识别并提取所截取部分的文字,是日常文字识别中的常用操作。
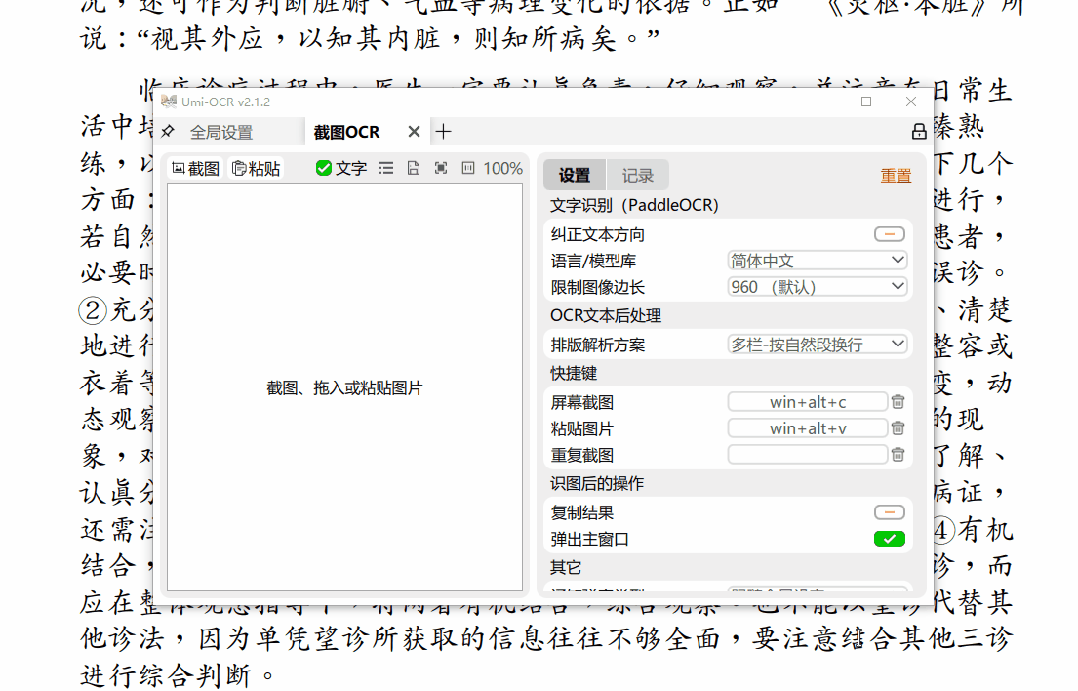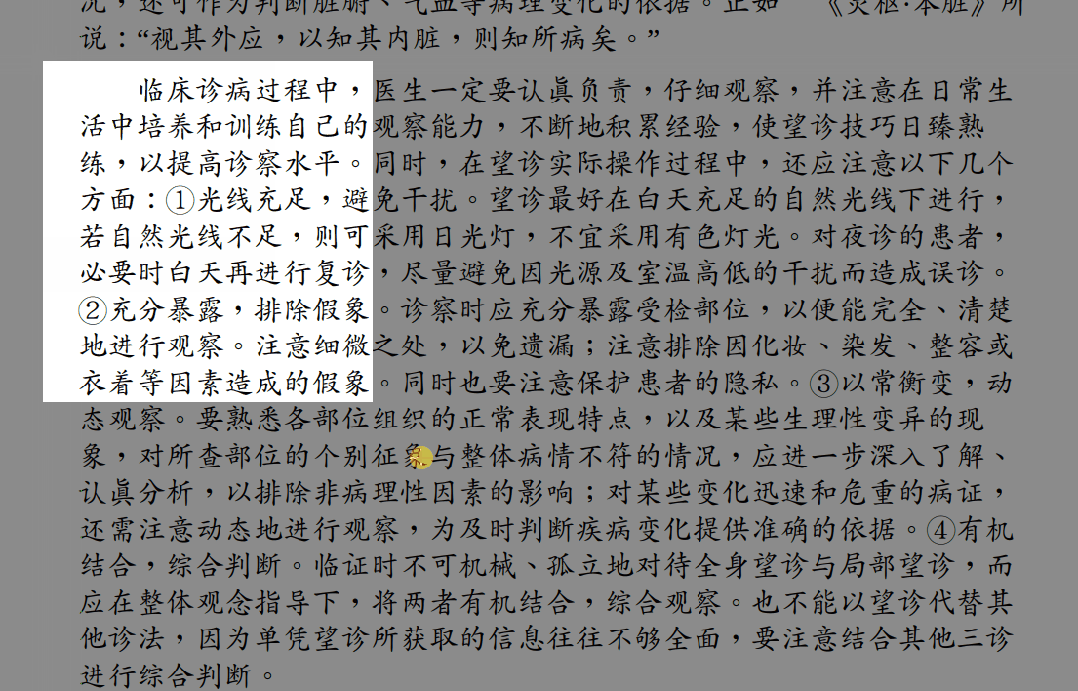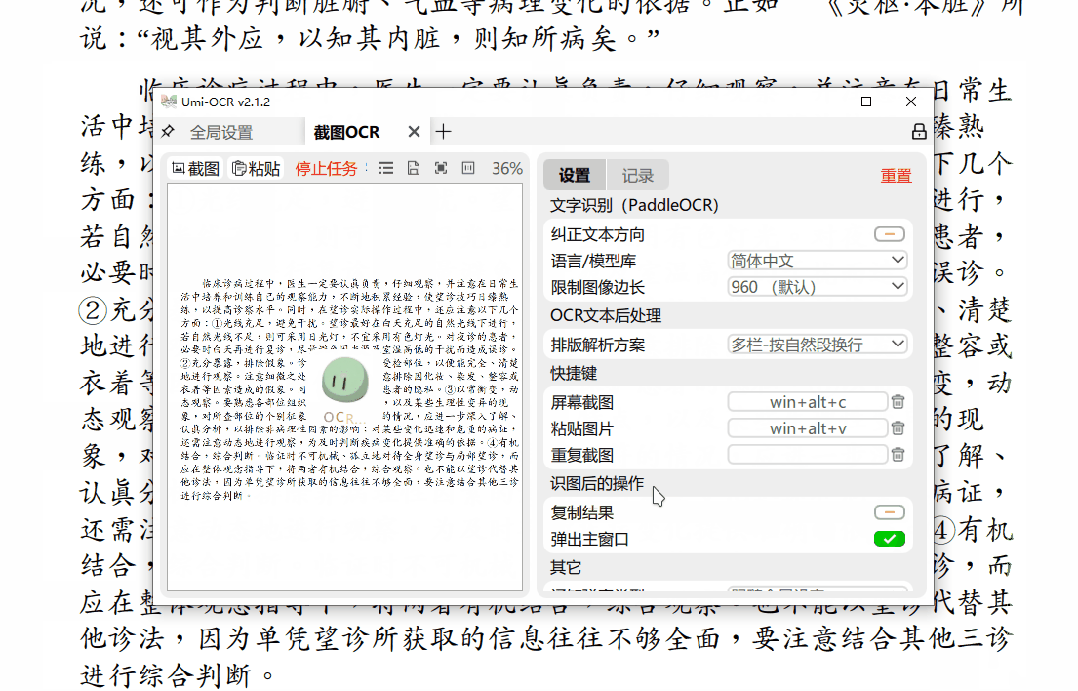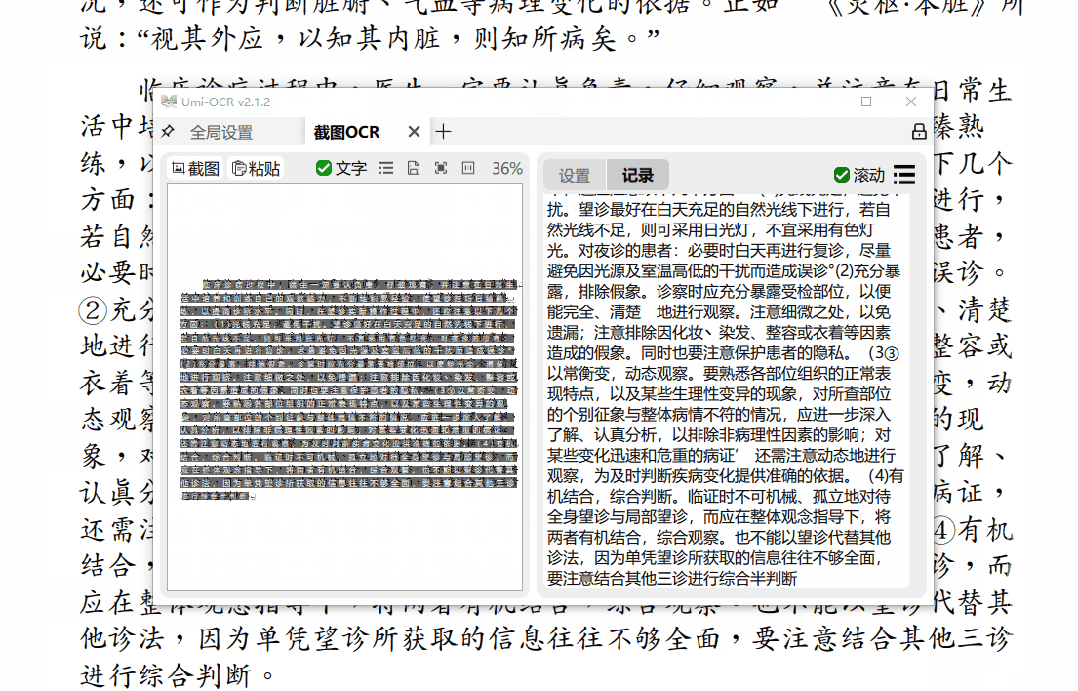
对于成功识别的文字,只需点击复制,即可将其复制到剪贴板。
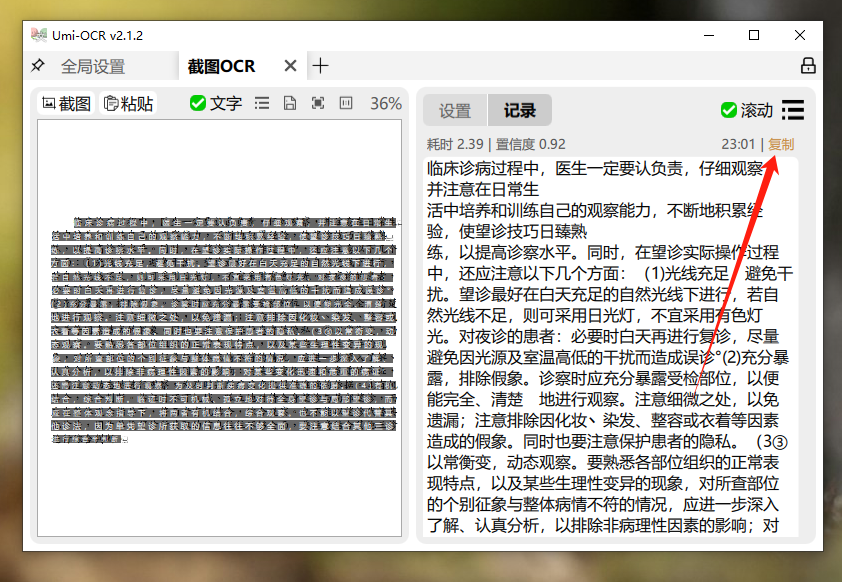
如果你有一堆含文字的图片需要识别,Umi-OCR的批量识别功能能够快速为你解决问题!这样的速度,真是无与伦比!
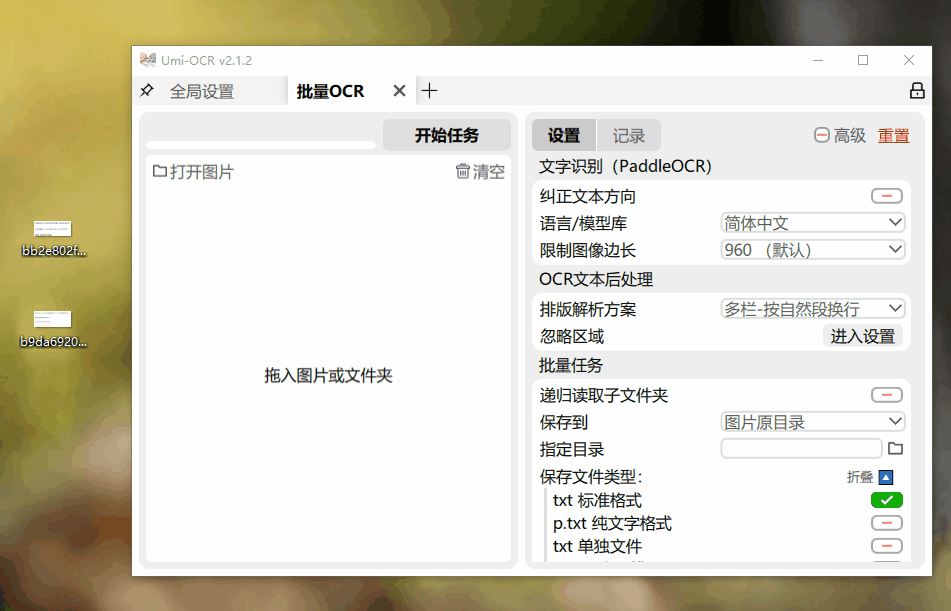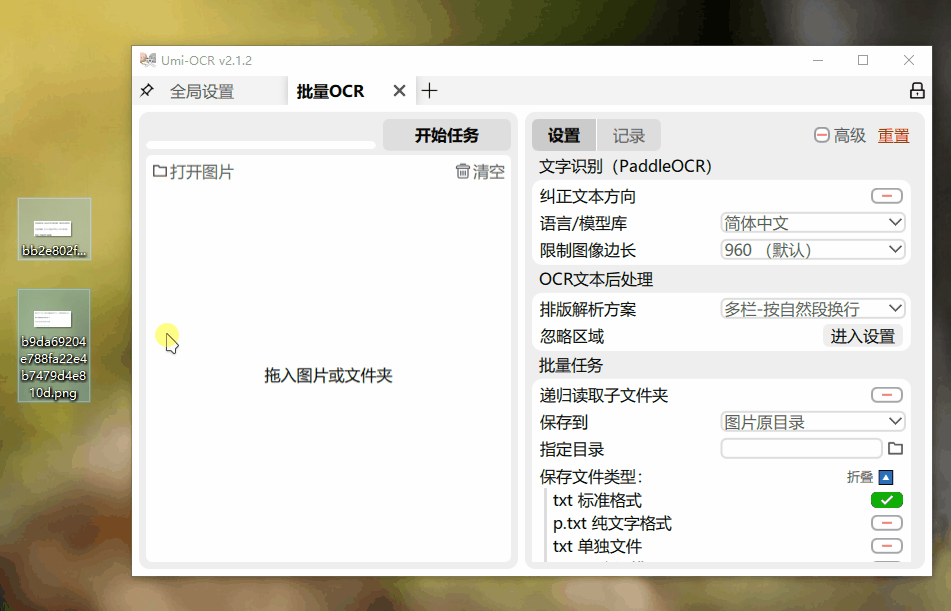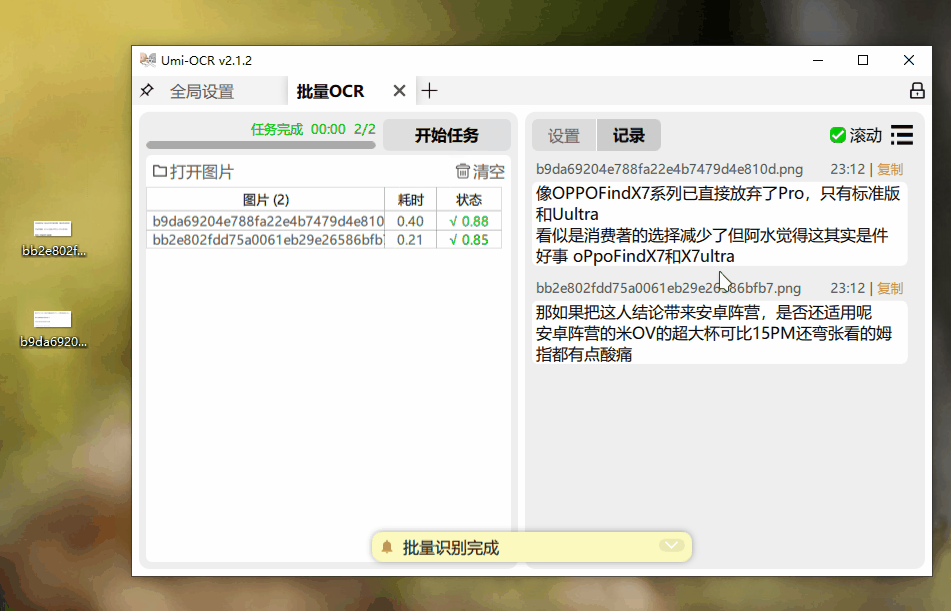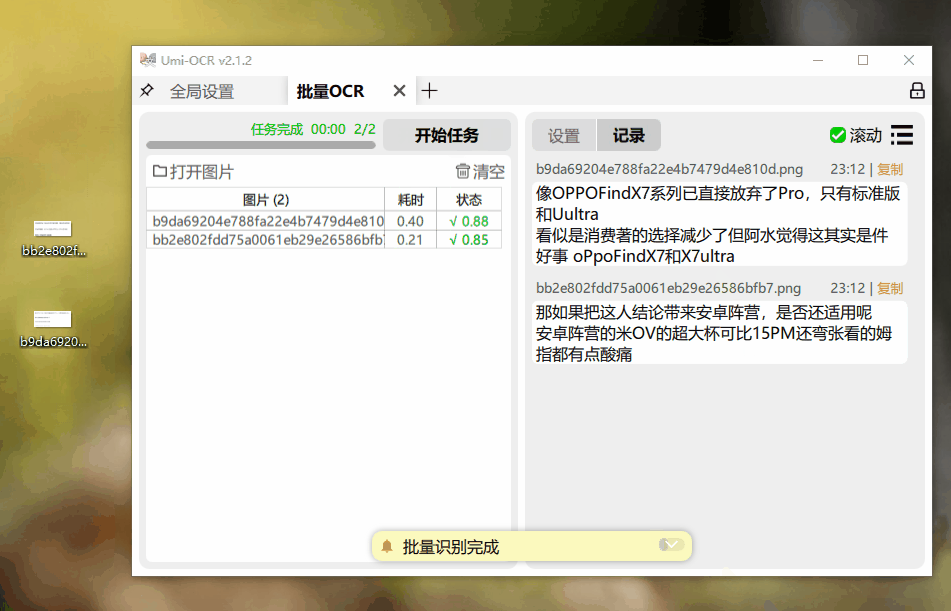
PDF文件的识别速度让人大吃一惊。一份9页的PDF文档,仅用几秒钟便被完美的提取出来。
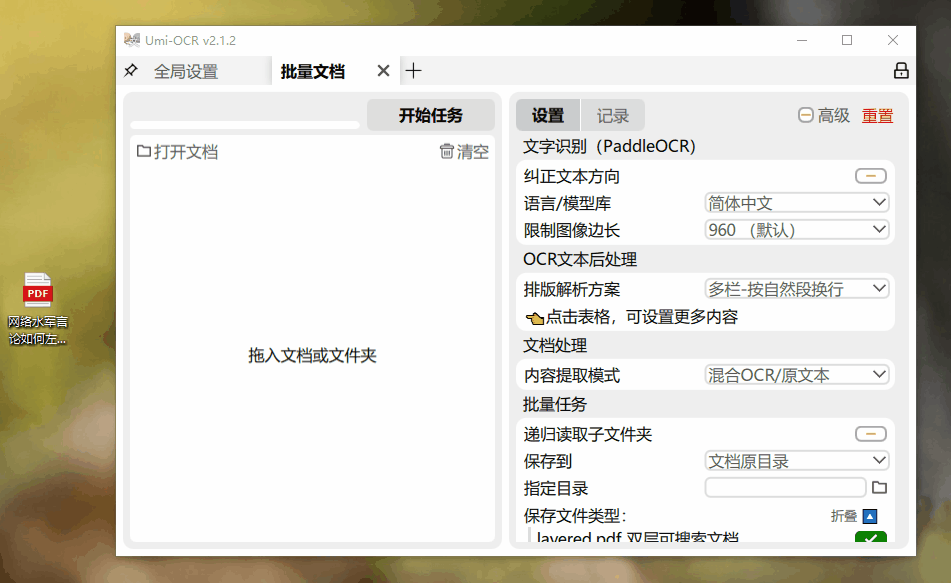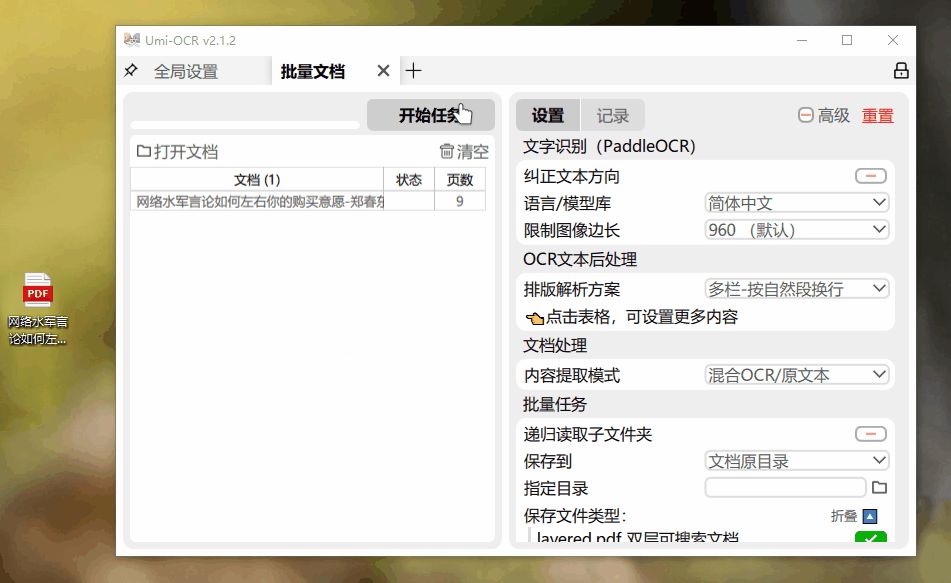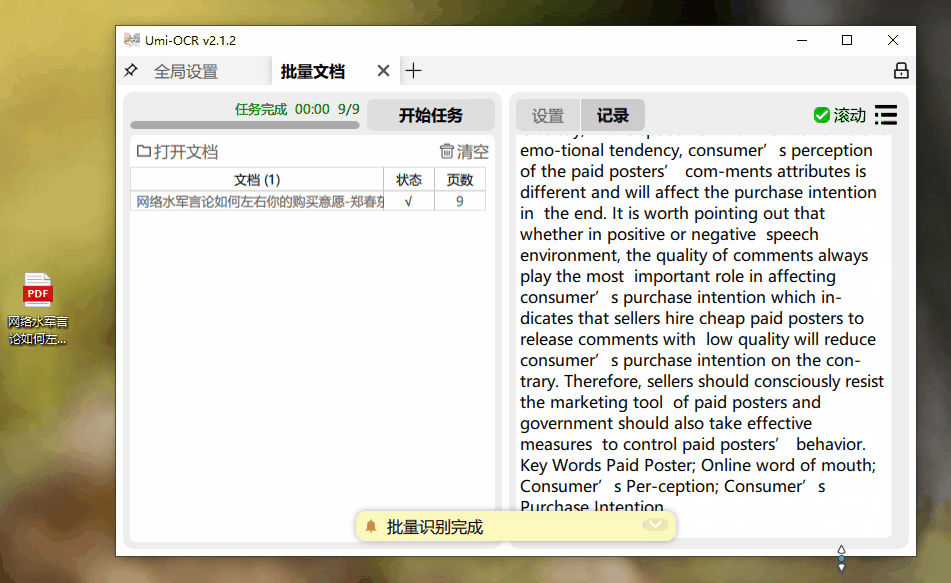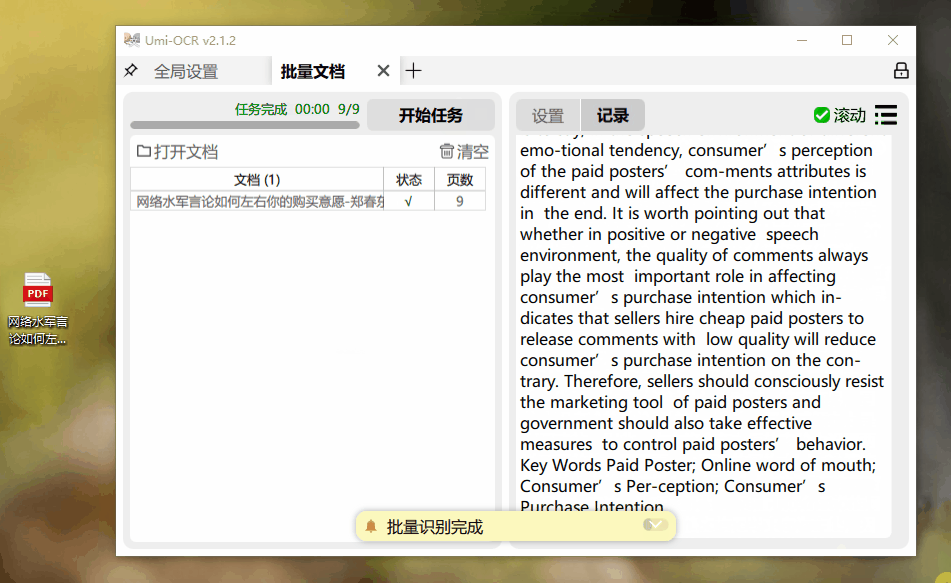
至于二维码识别,更是轻而易举,完美解决了电脑上没有摄像头时无法识别二维码信息的困扰。
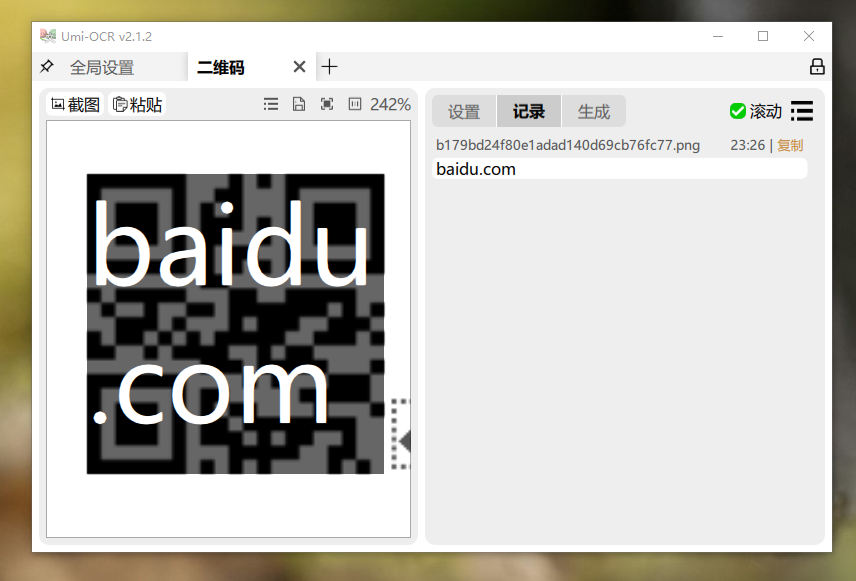
Umi-OCR的功能虽然简单,但对日常工作效率的提升却非常显著。
「Umi-OCR_Paddle_v2.1.4.7z.exe」