UVR5-UI是基于 python-audio-separator(即 UVR5
的命令行版本)开发的,提供了友好的可视化界面,使得用户无需掌握编程知识或命令行操作即可使用强大的音频处理功能。它支持多种模型和功能,包括:
-
所有主流音源分离模型:
-
VR Arch 模型
-
MDX-NET 模型
-
Demucs v4 模型
-
Mel-Band Roformer 和 BS Roformer 模型等
-
-
从视频网站下载并分离音频/视频:
- 支持通过
yt_dlp从 YouTube、Bilibili 等平台下载音频或视频,并进行分离。
- 支持通过
-
批量处理功能:
- 可以同时处理多个文件,节省时间。
-
多语言支持:
- 提供了多种语言界面,适合全球用户使用。
-
跨平台支持:
-
支持 Windows 和 Linux 系统。
-
还可以在 Colab、Kaggle、Lightning.ai 等在线平台上运行(适用于没有高性能硬件的用户)。
-
-
预编译版本:
- 提供了 ZIP 压缩包形式的预安装版本,方便快速上手。
-
Docker 部署支持:
- 支持在虚拟机或服务器上部署,适合高级用户或开发者。
对普通人有什么用?
对于非专业人士或普通用户来说,UVR5-UI是一个非常实用的工具,主要用于以下场景:
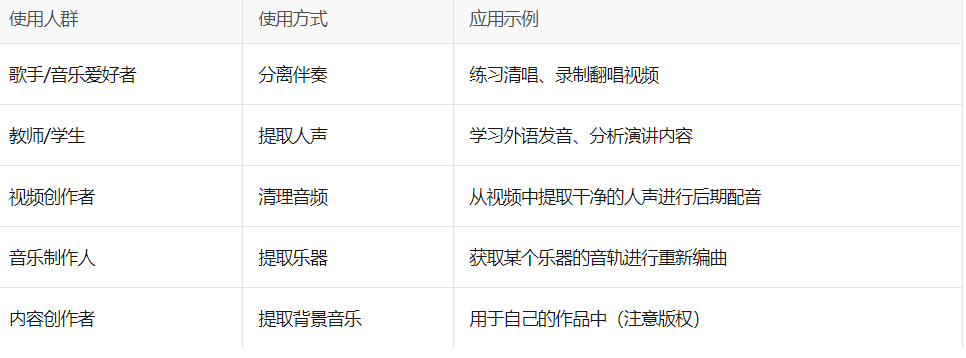
1. 音乐制作与翻唱
-
去除人声:可以将歌曲中的人声去掉,得到伴奏,用于练习唱歌、制作混音等。
-
提取人声:如果你喜欢一首歌中的演唱部分,可以用它单独提取出来。
2. 学习与教学
-
语言学习:可以从外语歌曲或视频中提取人声,帮助听力训练。
-
乐器学习:可以提取特定乐器的声音(如吉他、鼓),用于学习演奏技巧。
3. 视频创作者与主播
-
清理背景噪音:从视频中提取干净的人声,去掉背景杂音。
-
重新配音:提取原视频中的语音后,可替换为其他语言或风格的配音。
4. 内容创作
-
制作短视频素材:可以将视频中的音乐提取出来,用于自己的短视频作品中。
-
版权问题规避:通过分离出原始音乐,可以避免使用受版权保护的完整音频。
5. 修复老录音
- 如果你有一些老旧的录音,里面夹杂着噪音或其他声音,可以通过该工具尝试分离出清晰的人声或音乐。
使用场景举例
技术要求(普通人需要注意的地方)
虽然这是一个对普通人友好的工具,但仍然需要一定的硬件支持:
-
GPU 要求:推荐使用 NVIDIA RTX 2000 或更高系列显卡,否则处理速度会非常慢(尤其是 CPU 模式下)。
-
存储空间:至少 10GB 的磁盘空间。
-
网络依赖:如果使用在线服务(如 Colab/Kaggle),需要稳定的互联网连接。
-
安装依赖:需要安装 Git 和 FFmpeg(Windows 用户需配置环境变量 PATH)。
总结
UVR5-UI是一个功能强大但易于使用的音频分离工具,特别适合那些想从音乐或视频中提取特定音轨(如人声、伴奏、乐器)的普通用户。无论是学习、创作还是娱乐,它都能提供很大的帮助。即使你不具备技术背景,也可以通过其图形界面轻松完成复杂的声音处理任务。
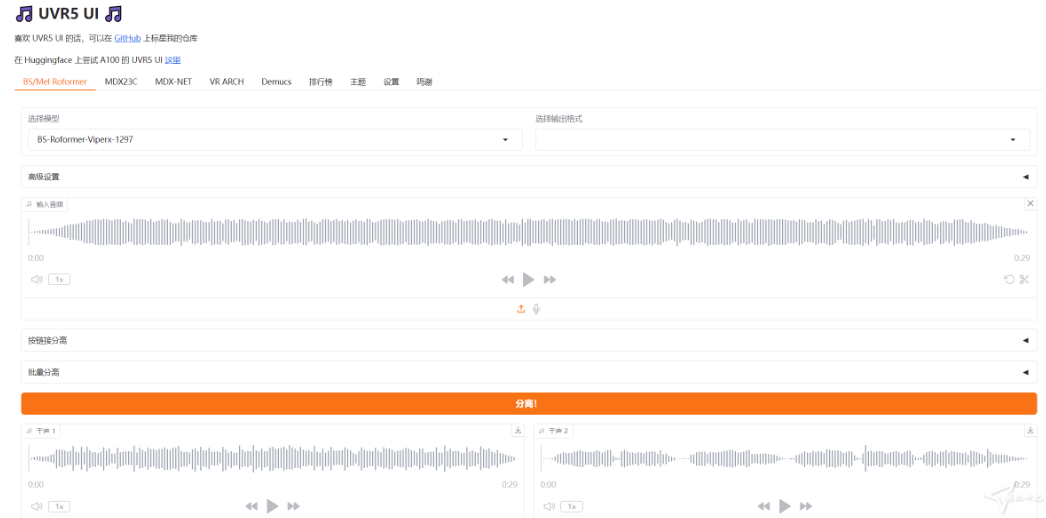
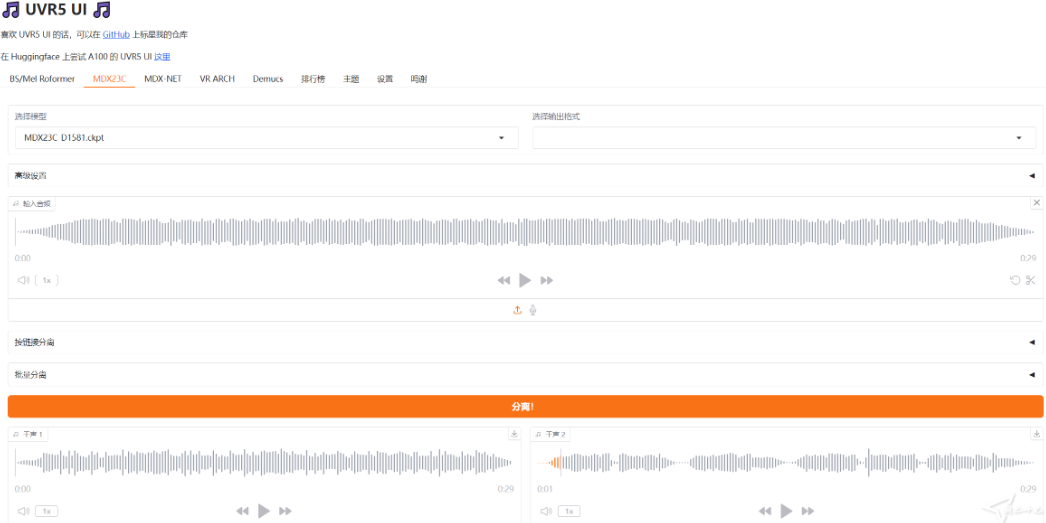
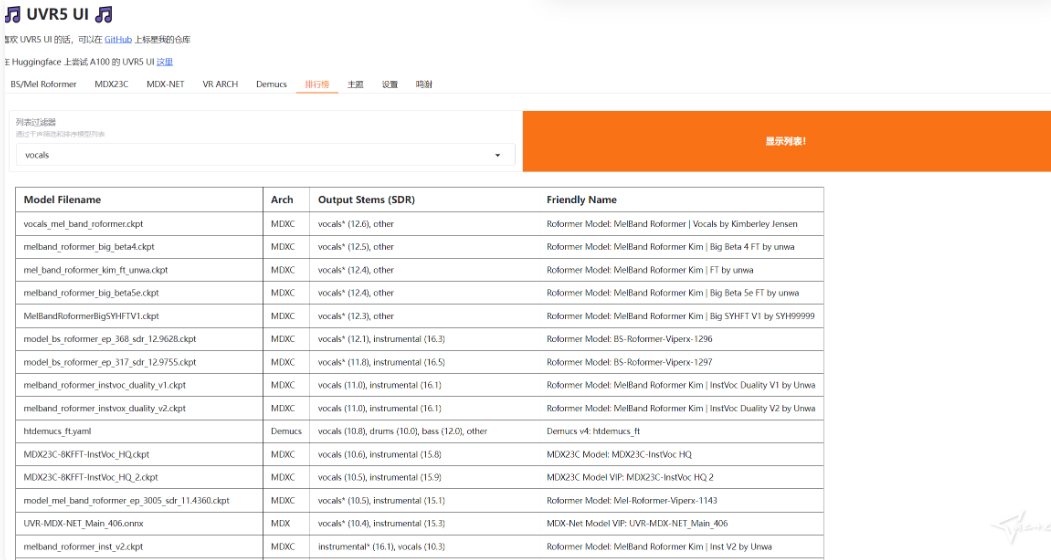
整合包说明:
1
自行安装好cuda12.4,不会安装去翻下这个教程![]() https://www.myhelen.cn/helen/259.htm
https://www.myhelen.cn/helen/259.htm
2 没有把所有的模型都放到压缩包里面,只放了每个工具的第一个模型。如果需要其他模型可以自行下载或者在models下载,我已经把所有的模型文件夹都下载好了放在models里面
3 未修改任何代码,保持原汁原味
4 这个开源项目的最大优势是把常见的一些音频分离的模型全部集合在了一起,简单省事,操作极其方便
5 对显卡要求极低,6g显卡就可以愉快玩耍,如果实在没有N卡。应该cpu也可以跑
6 本人win10 ltsc 4070ti spuer 完美运行
7 压缩包体积小,跟其他整合包相比 动不动就是几十G相比 这个就只有2.6G,算很轻巧了
下载地址