🧩 一、项目背景与痛点
还在手动复制PDF内容,逐段翻译、整理、总结吗?
你是否常常面对这样的问题:
-
• 从几十页PDF中提取关键信息,耗费一整天?
-
• 外文文献阅读吃力,翻译体验零散割裂?
-
• 扫描文件不能复制,只能看图硬啃?
我们打造的这款智能PDF阅读器,就是为了解决这些痛点而来!
无论你是科研人员、职场白领还是内容创作者,这款工具都能帮你用最快的方式提取价值信息,一键完成从阅读、翻译到摘要的全流程。

🧠 二、核心功能一览
这不仅仅是一个“PDF查看器”,它是一款AI增强型的文档处理平台,内置以下核心能力:
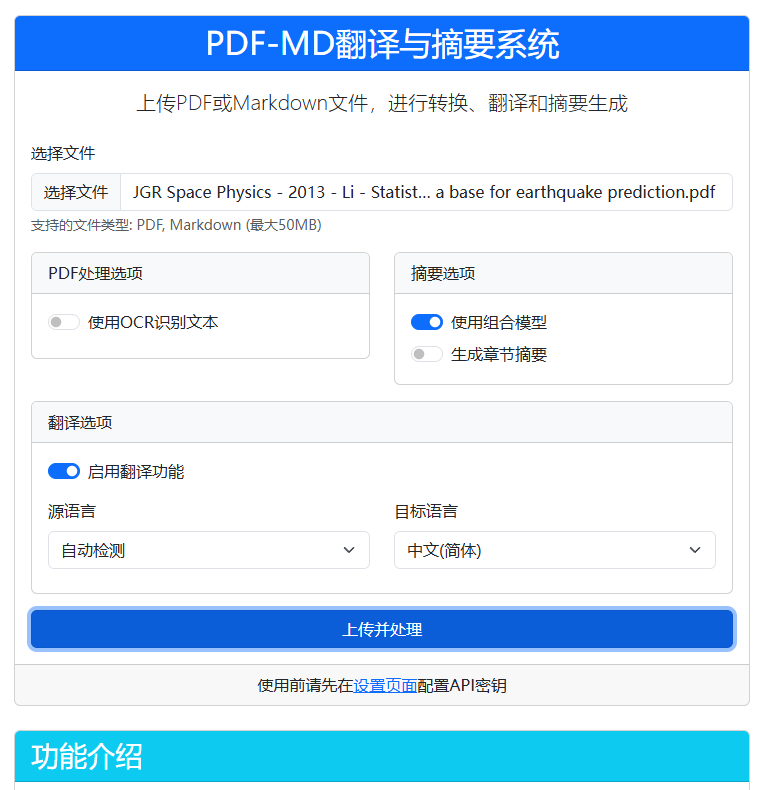
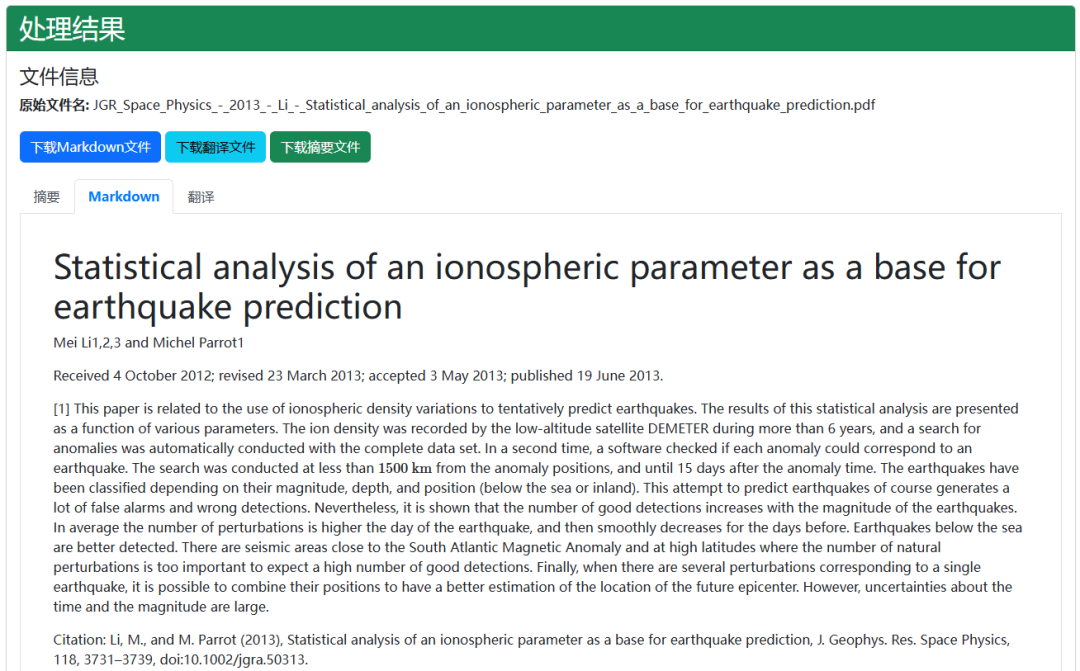
✅ 1. PDF转Markdown
将复杂PDF文档转为Markdown格式,保留标题、段落、表格、列表等结构,便于后续编辑、摘要、展示。
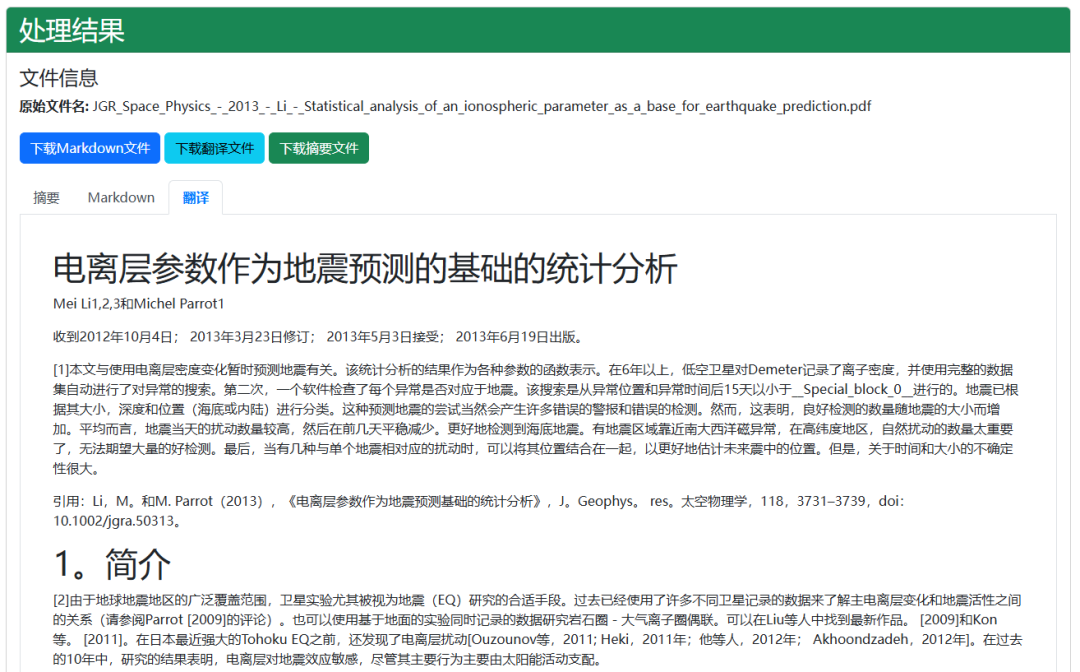
🌍 2. 多语言文档翻译
支持中英互译及多语种互译,自动识别语言,保留文档结构与格式。
🧾 3. 智能摘要生成
借助AI模型,一键生成全文摘要,支持整篇与分段总结,快速捕捉重点内容。
📷 4. OCR识别(图像转文字)
对于扫描类PDF,系统自动进行文字识别,将图片内容还原为可编辑文本。
🧩 5. 简洁直观的Web界面
基于Flask框架开发,提供文件上传、内容预览、摘要展示、翻译下载等功能,无需安装软件,打开网页即用。
🏗️ 三、技术架构解密
本项目采用模块化架构,便于扩展与维护,核心模块如下:
🌐 Web界面模块 web_ui.py
-
• 使用 Flask 提供 Web 服务
-
• 实现文件上传/下载、操作控制、预览展示
-
• 集成 Markdown 渲染器,支持代码高亮、表格展示
📄 PDF处理模块 pdf_reader.py, pdf_md.py
-
• 使用 PyPDF2 提取文本
-
• 结合 pdf2image + Magic_pdf 实现 PDF→图像→Markdown
-
• 内置 OCR 支持,兼容扫描类文件
🌍 翻译模块 translate_md.py
-
• 使用
deep-translator实现多语言翻译 -
• 保留 Markdown 结构,支持分段翻译与自动语言识别
✨ 摘要生成模块 summarize_md.py, TextSummaryComposite.py
-
• 调用 OpenAI 及兼容 API,实现文档摘要
-
• 支持不同模型配置、摘要策略组合
-
• 提供“整篇摘要”与“段落摘要”两种模式
🔁 四、处理流程图示(文字版)
-
1. 🖼️ 用户上传PDF文件
-
2. 🧠 系统解析→转为Markdown
-
3. 🌍 可选:翻译(多语种)
-
4. ✨ 可选:摘要生成(整篇/分段)
-
5. 📥 用户预览/下载处理结果(Markdown/HTML)
-
「Updf.zip」
链接:https://pan.quark.cn/s/1cbe96895d93